- Reinforcement Learning Basics
- Demo of RL
- Behavioral structure
- Evaluating a policy
- Evaluating a Learner
- Recap
本周三件事:看课程视频,阅读 Littman (1996) Chapters 1-2,作业2(HW2)。
以下为视频截图和笔记:
Reinforcement Learning Basics
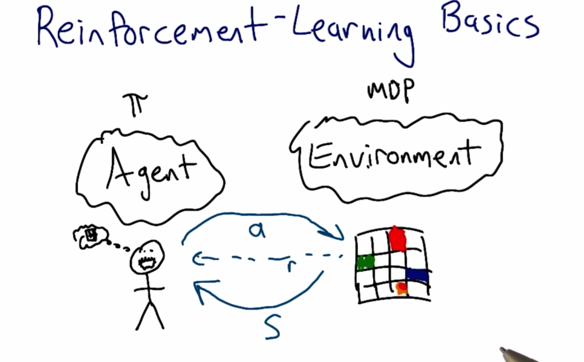
In RL, environment is only available to agent as percepted states (s), the agent can interact with the environment by taking action (a) and the environment gives a reward (r) as feedback to tell the agent is the pair are good or not. The computation is calculated in the agent's head.
The difference of RL and MDP is that in MDP, environment is totally available to the agent, while in RL, Environment is only available through the agent’s perception.
Demo of RL
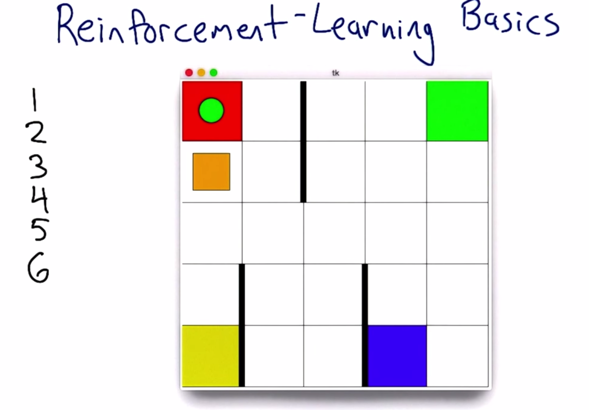
The small orange square represents the agent, and it can perform 6 actions. The world is the grid with some colored squares and a green dot. The goal what’s the game and what are the actions.
Behavioral structure
The goal is the generate learning algorithm
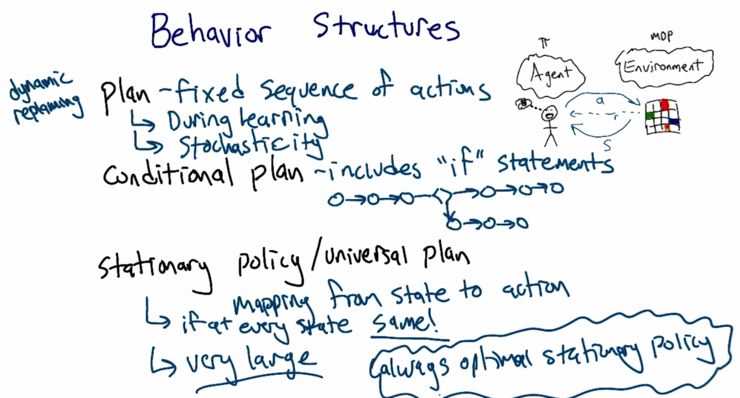
- Plan is a set of fixed actions. Plan won’t work during learning or when the environment is only partially known or stochastic.
- Conditional Plan includes “if” statements
- Stationary policy (or Universal Plan) are mapping from state to action. it can handle stochastic very well but it is very large. There always is an optimal stationary policy.
Evaluating a policy
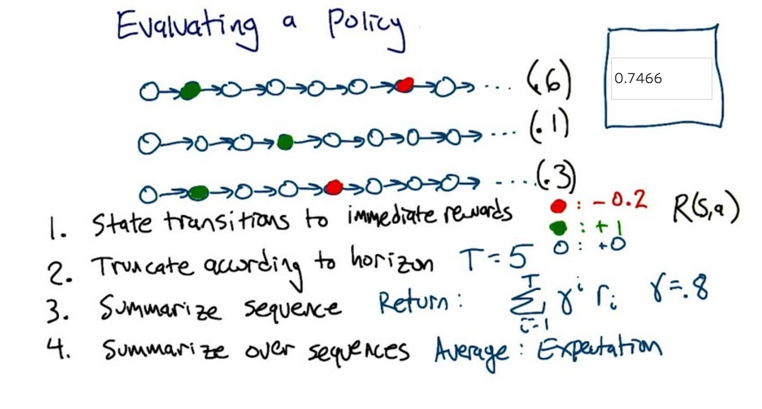
- The numbers in the parentheses are probabilities of choosing the sequence. R(s,a) is reward function. Return is discounted rewards.
- 0.8^1 * 0.6 + 0.8^3 * 0.1 +(0.8^1 +0.8^4(-0.2))0.3 = .746624
- This is the expected value of the policy based on the assumption that we index the states in each sequence from left to right starting at 0 on the far left. Interpreting T=5 to mean either truncating at the fifth circle or after the fifth transition (i.e. at the sixth circle) in each row gives the same result.
Evaluating a Learner

Recap

2015-08-31 初稿
2015-12-02 reviewed and revised