- Challenge Question
- a simple Bayes net
- Computing Bayes Rule
- conditional independence
- general definition of Bayes Network
- D Separation
- Probabilistic Inference
Week 07
This week you should watch Lesson 6, Bayes Nets, and read Chapter 14 in AIMA (Russell & Norvig). > Assignment 3: Bayes Nets Sampling Due: October 10 at 11:59PM UTC-12 (Anywhere on Earth time)
Challenge Question

-
given the Bayes net, what is the probability of P(O2 o1), that is the probability of the students get an offer from company 2 when s/he got an offer from company 1.

a simple Bayes net

- How many parameters (probabilities) are needed to specify the Bayes network above? (answer is 3)
Computing Bayes Rule
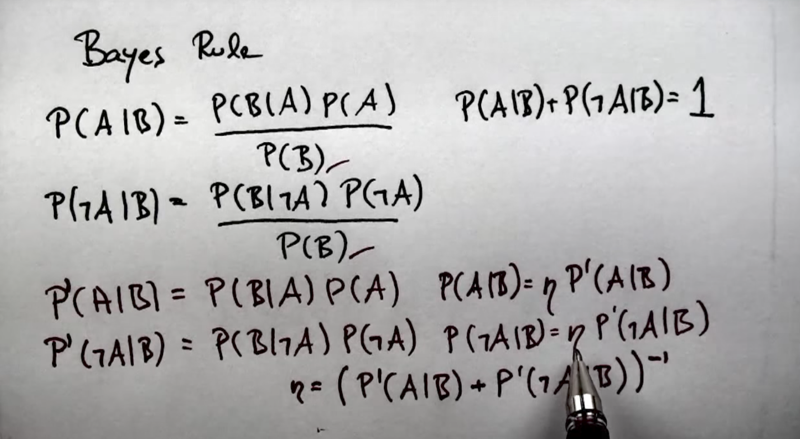
- the Bayes net can be calculated without knowing P(B) which is hard to calculate at first place.
-
Since we know P(A B) + P(-A B) = 1, we can use the pseudo probability method. We only calculate the numerator of the Bayse rule and normalize the result with a normalization factor.
Two Test Cancer example

- note here
P(C|+,+) =P(c, +,+)/[P(c,+,+) + P(-c,+,+)]

- simillary,
P(C|+,-) =P(c, +,-)/[P(c,+,-) + P(-c,+,-)]
conditional independence

- When C is known, T1 and T2 are independent.
- what if we don’t know C?
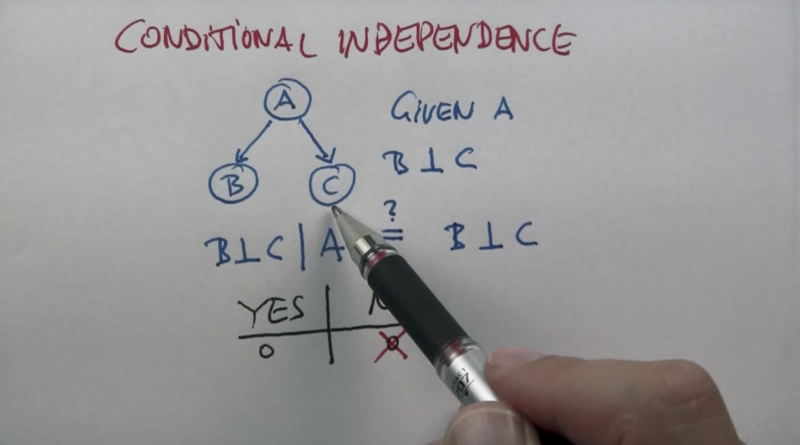
- the answer is that not knowing C, T1 and T2 might not be independent.

-
the hard part for me is to come up with __P(+2 +1)=P(+2 +1,C)P(c +1) + P(+2 +1,-C)P(-C +1)__ -
_the calculation of P(C +1) is covered in the lecture of Week 06._ __P(C +1) = P(+1 C)P(C)/P(+1)__
the relationship between absolute and conditional independence
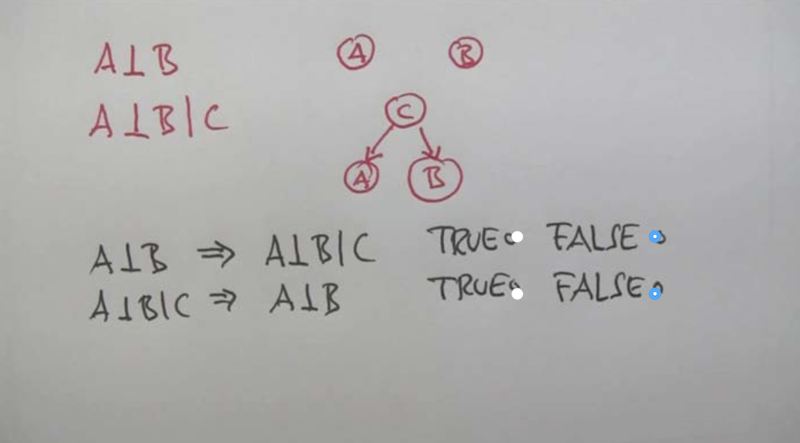
Independence
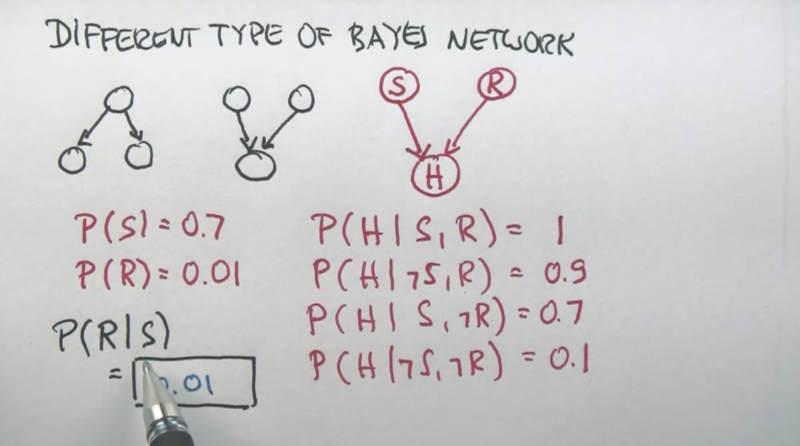
- S and R (Sunny and Raise) are not related in the Bayes Network

- still the first part of the Bayes rule, I did not get
-
the point here that the lecture is trying to make is that P(R S) = P(R) since R and S are independent - this is called Away effect

-
apply Bayes rule so that P(R H) = P(H R)*P(R)/P(H), P(H) is known - calculate P(H) is the key here
-
P(H R) is easy, the steps are similar to the calculation of P(H)

-
Similar to the P(R S,H)
Conditional Dependence

- we know that R and S are independent, but adding the information about H, it created a dependence between the two. E.g. being happy in a not-Sunny day increases the probability of raise.

general definition of Bayes Network
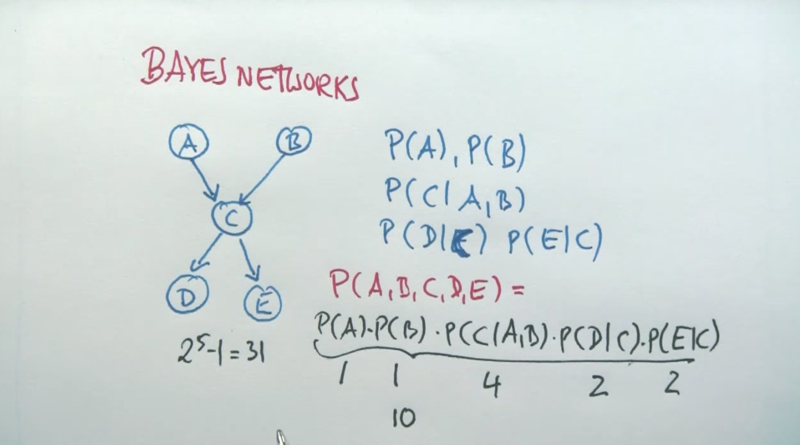

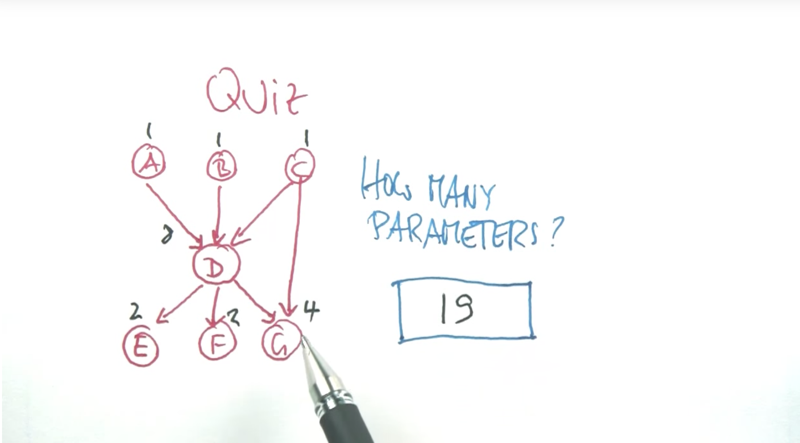
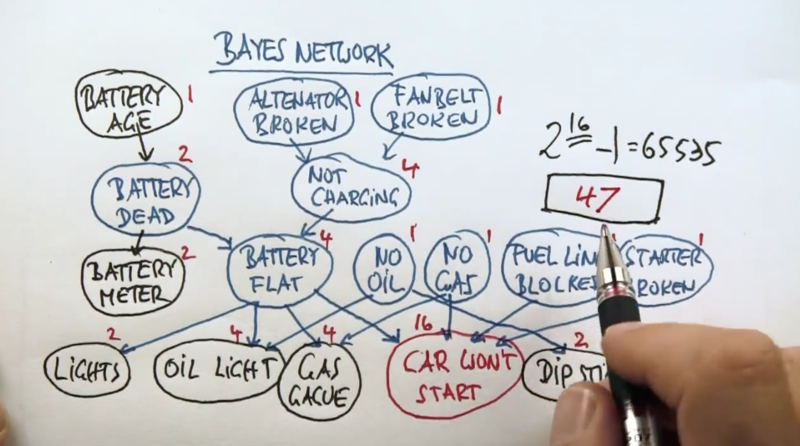
- the quizzes above showed the advantage of Bayes network v.s. unstructured networks. Bayes net is more concise.
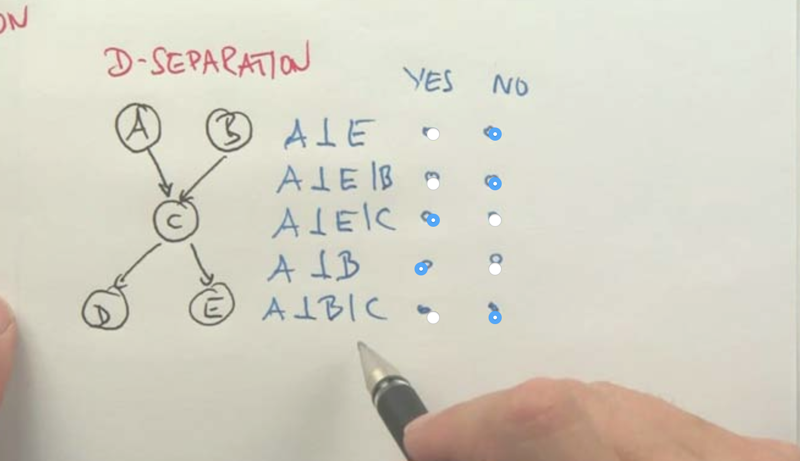
D Separation
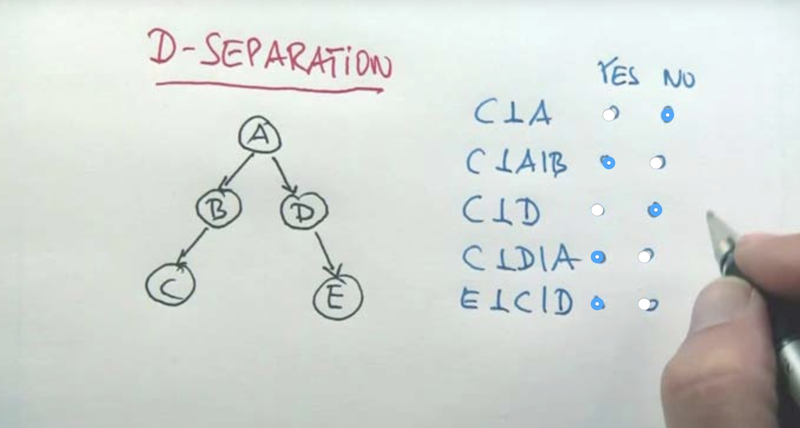
- A and C are not independent because A can determine B and then determine A through B. But if B is known, then A becauses irrelevant.
- C and D is not independent because knowing D can infer the knowledge of A and then can influence C. But if A is known, then D can not inference A or C anymore.
- E and C are similar to C and D, they are independent if A, B, or D is known. if A, B, D is unknown, the C and E can be dependent.
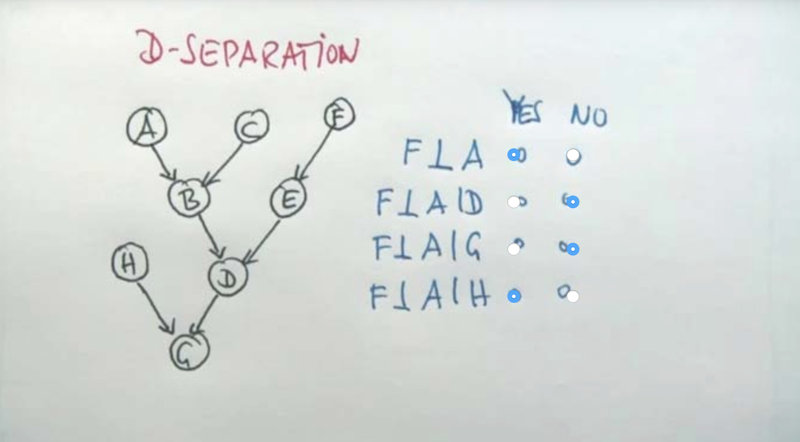
- A matters in determine E so does B. Because Both A and B can influence C and C influence E. If C is known, A or B becomes irrelevant to E.
- A and B are independent but if C is known, we can use A to infer B or vice versa. they are then not independent anymore in the case that C is known. This is the explain away effect.
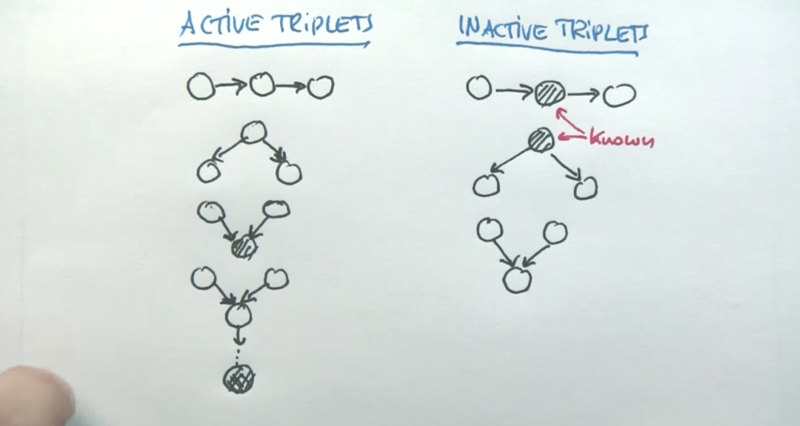
- Active means dependence of the nodes the unknown nodes.
- notice that the third one is the application of the last rule in the previous slide.
Now the application of Bayes Network:
Probabilistic Inference
In the remaining part of this lesson, you will learn about probabilistic inference using Bayes Nets, i.e. how to answer questions that you are interested in, given certain inputs.
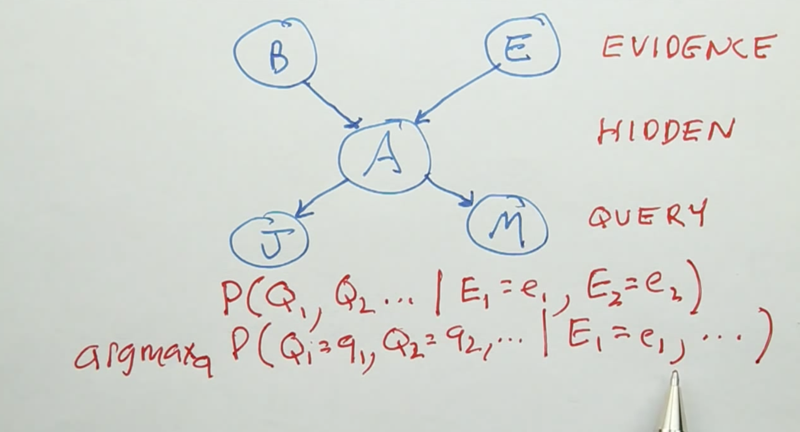
- With Bayes net, we can infer the probability distribution of some nodes given certain input.
- the input is called evidence, the output is called Query and all the other nodes are called Hidden nodes.
|  |
Enumeration

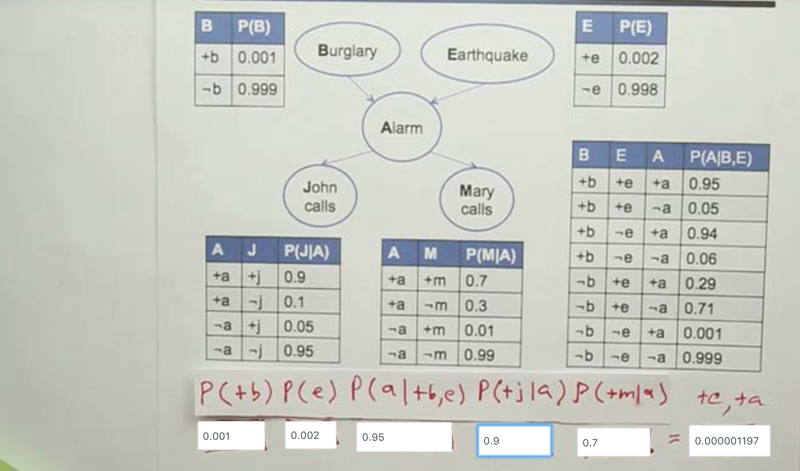
The calculation becomes reading from the Bayes net table and summarize them. But when the number of nodes becomes larger, this method requires a lot of calculation.

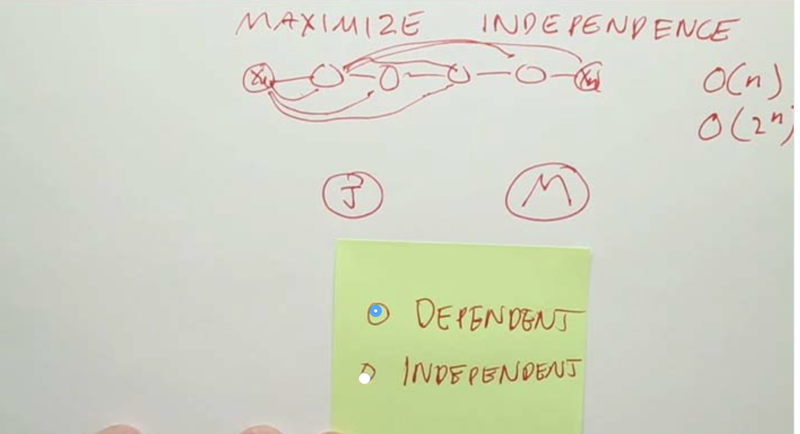
- e.g., if A is unknown, J and M are dependent.
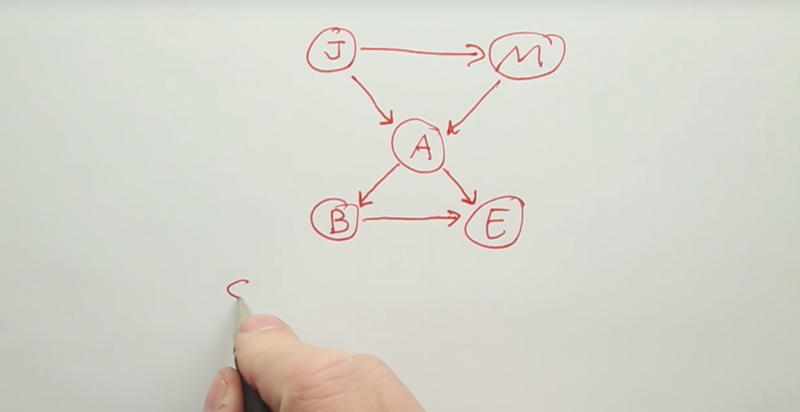
Bayes net in Causal direction
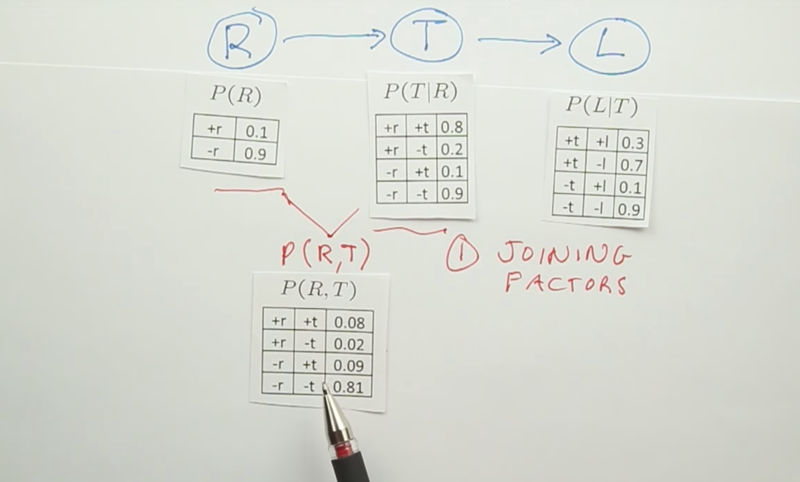
Value elimination
Value elimination is a two-step operation: eliminate some fac Joining factors and elimination

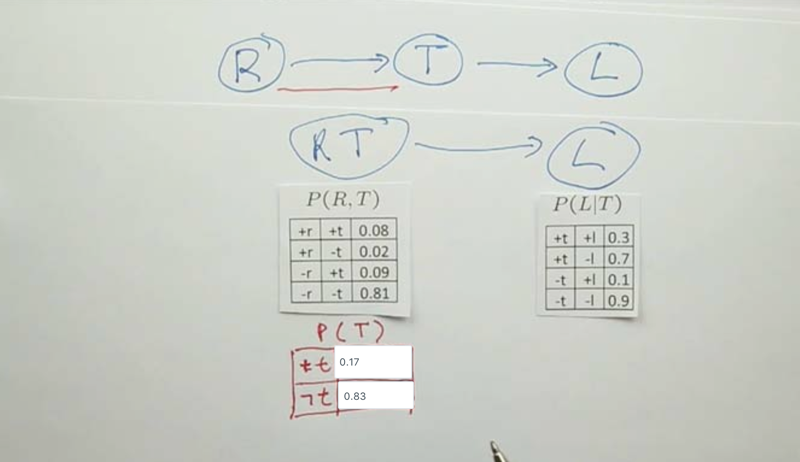


Approximate Inference

- the sampling procedure will get the probability distribution to be close to the truth if repeated infinitely. This is called consistent.
- the sampling method can be used to generate the complete joint probability or individual probability
-
to generate conditional probability, we can still use the sampling method, but need to cross-off the irrelevant joint probabilities. E.g, if we need to know P(R C), then all the cases when c is not true will need to be thrown away. this is called rejection sampling.
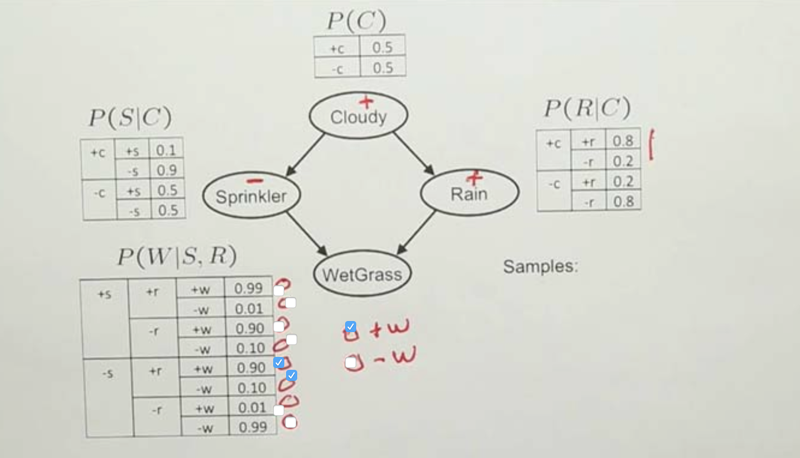
Rejection Sampling
- the problem of rejection sampling is that when the condition we care about is at a lower odds, the rejection sampling will reject a lot of samples which is a waste of resources. We can solve the problem by fixing the conditional variable, this is called likelihood weighting.

- the problem of likelihood weighting, is that it is inconsistent. In another word, sampling with likelihood weighting cannot get true probability distribution unless it is properly weighted.
Likelihood Weighting
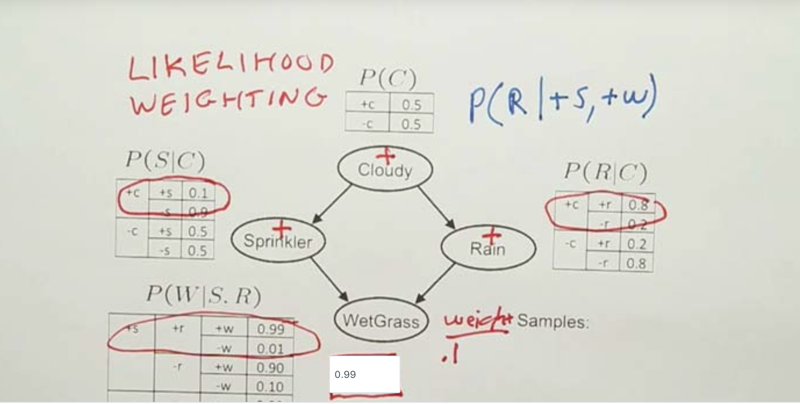
-
Specify the weight for w+ and +s when constraining them when sampling. In the quiz, we need to constrain the +2 with the probability of 0.99 since we already know its parents are +S(due to constraining) and +R(due to sampling).
- With likelihood weighting, we can make rejection sampling consistent
- but it does not solve all the problems, for example
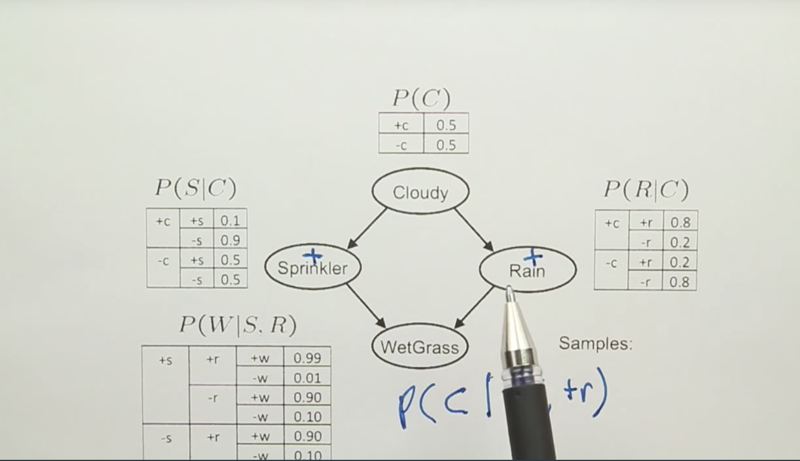
- Likelihood weighting with sampling will get good values for WetGrass because S and R determine W.
- However, the sampling of C will not look at S or R, so the process will still generate C with values that do not go well with R and S, in this case, a lot of rejections will happen.
Gibbs Sampling
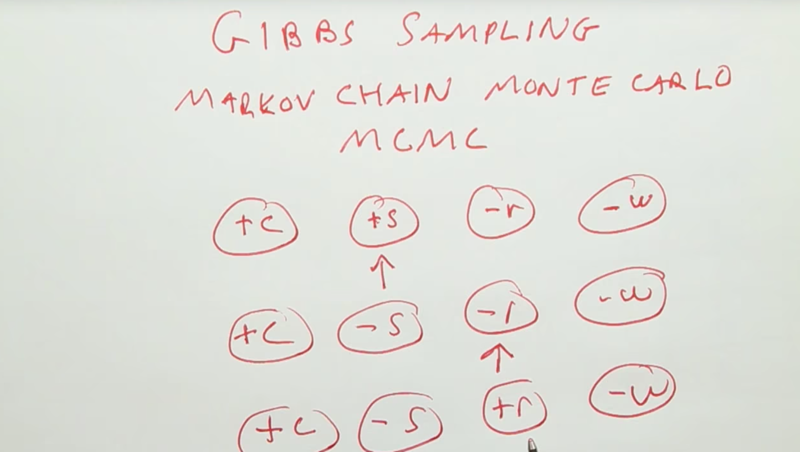
- Markov Chain Monte Carlo (MCMC): 1) sample by randomly sampling all nodes at the first time, then, 2) randomly identify one node from the first sample, and resample the node while keeping all others consistent with the first one to generate the second sample, and 3) repeat 2) with the second sample to generate the third sample, and so on…
- MCMC is consistent.
Monty Hall Problem

- Even Monty Hall himself does not understand the Monty Hall problem.